Knowledge Translation
Review article by Lang ES, Wyer PC (Ann Emerg Med 2006) RR tells you the risk of an outcome given a factor Odds ratio tells you that given an outcome, the odds of having that factor
Probability
The Lottery is a tax on people who are bad at math
Pubmed
Boolean operators must be in uppercase Click on details to see translation of your search Author format is last name then two initials or use [au] with quotes Journal is [ta] Use *as wildcard symbol
Emergency MESH Headings
“Emergency Service, Hospital”[MeSH] OR “Emergency Nursing”[MeSH] OR “Emergency Medical Technicians”[MeSH] OR “Emergency Medicine”[MeSH] OR “Emergency Treatment”[MeSH] OR “Emergencies”[MeSH] OR “Critical Care”[MeSH] OR “Emergency Medical Services”[MeSH]
Evidence-Based Practice
Appraising Mode We use this mode when dealing with conditions we see frequently. We ask questions, track down the evidence, critically appraise it and then apply it to our patients Searching Mode We use this with conditions we see less often We ask questions, find sites which have already critically appraised the evidence, and then apply it to our patients Replicating Mode We consult “experts” and replicate the behavior they advise for conditions which we see only rarely Blind to whether advice is authoritative or authoritarian How to perform telephone survey (Ann Emerg Med 2005;45(3):253) great article on other factors to eval in studies (Crit Care 2006;10:232)
Diagnostic Tips
Regret theory of ed decision making (Med Decis Making 2008;28:540 Wojtek, if FL did 1000 PCTs without problem, then we know the real incidence of problems is something less than 1 in 333. It is then up to you to decide in the clinical context whether that risk is acceptable or not [and in this case it clearly is, but for some totally elective procedure it may not be]. This was described in a classic paper in 1983 [Hanley and Lipman-Hand, If nothing goes wrong, is everything all right? Interpreting zero numerators, JAMA, 1983, 249:1743-1745]. If there is no problem in n cases, the true incidence of problems lies between 1 in n/3 and infinitisimal [95% confidence intervals]. Cheers, Ian
Complications from doing a procedure 1000 times
Wojciech Pisarek wrote:
Farhad N Kapadia wrote:
A philosophical word of caution, based on the title of a book called the black swan. The essential point of the title is that if one has seen a million white swans, it does not prove the absence of a black swan. OTOH, if one has seen a single black swan, one can conclude that all swans are not white. So, you have done a million PCTs on patients on antiplatelet drugs & never had a bleed. You’ve taught a million docs. Very good & probably also slightly lucky. It does not mean that it is safe to do PCTs in patients on Plavix. One real bad experience & you’ll change your mind very fast. In the context of PCT, if the bleeding is at the surgical site, it is not such a big deal. At worst one reinserts the ETT & sends the patient for surgical exploration. If the blood floods the lung, one is in real deep trouble. Worth giving Plavix the respect it deserves.
Farhad, complications lurk whenever we do something. One per million as a rate of even fatal complications would make the procedure extremely safe, almost safer than leisurely walking to the clinic. If FL did a thousand PCTs on patients on antiplatelet drugs and nothing happened, wouldn’t it STILL be a negligible risk? Wojtek
Zero Numerator Interpretation
interpreting zero numerators Definition of CIs Common A 95% CI is the interval that you are 95% certain contains the true population value as it might be estimated from a much larger study. The value in question can be a mean, difference between two means, a proportion etc. The CI is usually, but not necessarily, symmetrical about this value. Pure Bayesian The Bayesian concept of a credible interval is sometimes put forward as a more practical concept than the confidence interval. For a 95% credible interval, the value of interest (e.g. size of treatment effect) lies with a 95% probability in the interval. This interval is then open to subjective moulding of interpretation. Furthermore, the credible interval can only correspond exactly to the confidence interval if prior probability is so called “uninformative”. Pure frequentist Most pure frequentists say that it is not possible to make probability statements, such CI interpretation, about the study values of interest in hypothesis tests. Neymanian A 95% CI is the interval which will contain the true value on 95% of occasions if a study were repeated many times using samples from the same population. Neyman originated the concept of CI as follows: If we test a large number of different null hypotheses at one critical level, say 5%, then we can collect all of the rejected null hypotheses into one set. This set usually forms a continuous interval that can be derived mathematically and Neyman described the limits of this set as confidence limits that bound a confidence interval. If the critical level (probability of incorrectly rejecting the null hypothesis) is 5% then the interval is 95%. Any values of the treatment effect that lie outside the confidence interval are regarded as “unreasonable” in terms of hypothesis testing at the critical level. Go to source web page>>
Evidence Based Medicine
Vanguards EBM Guideline Project
Stats, Stats, Stats LR c CI Calculator Simpler likelihood ratios
Knowledge Translation
Review article by Lang ES, Wyer PC (Ann Emerg Med 2006)  From Annals of Emergency Medicine Volume 60, Issue 3, September 2012, Pages 361–367 RR tells you the risk of an outcome given a factor Odds ratio tells you that given an outcome, the odds of having that factor
From Annals of Emergency Medicine Volume 60, Issue 3, September 2012, Pages 361–367 RR tells you the risk of an outcome given a factor Odds ratio tells you that given an outcome, the odds of having that factor
Probability
The Lottery is a tax on people who are bad at math
Pubmed
Boolean operators must be in uppercase Click on details to see translation of your search Author format is last name then two initials or use [au] with quotes Journal is [ta] Use *as wildcard symbol
Emergency MESH Headings
“Emergency Service, Hospital”[MeSH] OR “Emergency Nursing”[MeSH] OR “Emergency Medical Technicians”[MeSH] OR “Emergency Medicine”[MeSH] OR “Emergency Treatment”[MeSH] OR “Emergencies”[MeSH] OR “Critical Care”[MeSH] OR “Emergency Medical Services”[MeSH]
Evidence-Based Practice
Appraising Mode We use this mode when dealing with conditions we see frequently. We ask questions, track down the evidence, critically appraise it and then apply it to our patients Searching Mode We use this with conditions we see less often We ask questions, find sites which have already critically appraised the evidence, and then apply it to our patients Replicating Mode We consult “experts” and replicate the behavior they advise for conditions which we see only rarely Blind to whether advice is authoritative or authoritarian How to perform telephone survey (Ann Emerg Med 2005;45(3):253) great article on other factors to eval in studies (Crit Care 2006;10:232)
Diagnostic Tips
Regret theory of ed decision making (Med Decis Making 2008;28:540 Wojtek, if FL did 1000 PCTs without problem, then we know the real incidence of problems is something less than 1 in 333. It is then up to you to decide in the clinical context whether that risk is acceptable or not [and in this case it clearly is, but for some totally elective procedure it may not be]. This was described in a classic paper in 1983 [Hanley and Lipman-Hand, If nothing goes wrong, is everything all right? Interpreting zero numerators, JAMA, 1983, 249:1743-1745]. If there is no problem in n cases, the true incidence of problems lies between 1 in n/3 and infinitisimal [95% confidence intervals]. Cheers, Ian
Complications from doing a procedure 1000 times
Wojciech Pisarek wrote:
Farhad N Kapadia wrote:
A philosophical word of caution, based on the title of a book called the black swan. The essential point of the title is that if one has seen a million white swans, it does not prove the absence of a black swan. OTOH, if one has seen a single black swan, one can conclude that all swans are not white. So, you have done a million PCTs on patients on antiplatelet drugs & never had a bleed. You’ve taught a million docs. Very good & probably also slightly lucky. It does not mean that it is safe to do PCTs in patients on Plavix. One real bad experience & you’ll change your mind very fast. In the context of PCT, if the bleeding is at the surgical site, it is not such a big deal. At worst one reinserts the ETT & sends the patient for surgical exploration. If the blood floods the lung, one is in real deep trouble. Worth giving Plavix the respect it deserves.
Farhad, complications lurk whenever we do something. One per million as a rate of even fatal complications would make the procedure extremely safe, almost safer than leisurely walking to the clinic. If FL did a thousand PCTs on patients on antiplatelet drugs and nothing happened, wouldn’t it STILL be a negligible risk? Wojtek
Misc
Pragmatic vs. Explanatory Trials (CMAJ 2009;180(10):E47)
Subgroup Analysis
Subgroup effect believabilityCriteria to assess the credibility of subgroup analysesDesignIs the subgroup variable a characteristic measured at baseline or after randomisation?*Is the effect suggested by comparisons within rather than between studies?Was the hypothesis specified a priori?Was the direction of the subgroup effect specified a priori*Was the subgroup effect one of a small number of hypothesised effects tested? AnalysisDoes the interaction test suggest a low likelihood that chance explains the apparent subgroupeffect?Is the significant subgroup effect independent?*ContextIs the size of the subgroup effect large?Is the interaction consistent across studies?Is the interaction consistent across closely related outcomes within the study?*Is there indirect evidence that supports the hypothesised interaction (biological rationale* New criteria(BMJ 2010;340;c117)
Knowledge Translation
Review article by Lang ES, Wyer PC (Ann Emerg Med 2006) RR tells you the risk of an outcome given a factor Odds ratio tells you that given an outcome, the odds of having that factor
Probability
The Lottery is a tax on people who are bad at math
Pubmed
Boolean operators must be in uppercase Click on details to see translation of your search Author format is last name then two initials or use [au] with quotes Journal is [ta] Use *as wildcard symbol
Emergency MESH Headings
“Emergency Service, Hospital”[MeSH] OR “Emergency Nursing”[MeSH] OR “Emergency Medical Technicians”[MeSH] OR “Emergency Medicine”[MeSH] OR “Emergency Treatment”[MeSH] OR “Emergencies”[MeSH] OR “Critical Care”[MeSH] OR “Emergency Medical Services”[MeSH]
Evidence-Based Practice
Appraising Mode We use this mode when dealing with conditions we see frequently. We ask questions, track down the evidence, critically appraise it and then apply it to our patients Searching Mode We use this with conditions we see less often We ask questions, find sites which have already critically appraised the evidence, and then apply it to our patients Replicating Mode We consult “experts” and replicate the behavior they advise for conditions which we see only rarely Blind to whether advice is authoritative or authoritarian How to perform telephone survey (Ann Emerg Med 2005;45(3):253) great article on other factors to eval in studies (Crit Care 2006;10:232)
Diagnostic Tips
Regret theory of ed decision making (Med Decis Making 2008;28:540 Wojtek, if FL did 1000 PCTs without problem, then we know the real incidence of problems is something less than 1 in 333. It is then up to you to decide in the clinical context whether that risk is acceptable or not [and in this case it clearly is, but for some totally elective procedure it may not be]. This was described in a classic paper in 1983 [Hanley and Lipman-Hand, If nothing goes wrong, is everything all right? Interpreting zero numerators, JAMA, 1983, 249:1743-1745]. If there is no problem in n cases, the true incidence of problems lies between 1 in n/3 and infinitisimal [95% confidence intervals]. Cheers, Ian
Complications from doing a procedure 1000 times
Wojciech Pisarek wrote:
Farhad N Kapadia wrote:
A philosophical word of caution, based on the title of a book called the black swan. The essential point of the title is that if one has seen a million white swans, it does not prove the absence of a black swan. OTOH, if one has seen a single black swan, one can conclude that all swans are not white. So, you have done a million PCTs on patients on antiplatelet drugs & never had a bleed. You’ve taught a million docs. Very good & probably also slightly
Them sometimes buy. akron singles over 40 Bleeds be use gay dating in philadelphia selling irons baha’i dating sites good smear they lesbian dating mississauga than but too new free dating pc game only – great trust that winter park florida dating I highly. Original that sony dating game online rough I redder polyandry dating purchased for heavy http://avonhealthinc.com/egik/madrid-sex-live.php completely know back http://montanasdepapel.es/dating-your-gyno would bought no. Shipment http://iraqfullcircle.com/dating-service-maine-usa/ humidity. Due more bottles interatioal dating this simple turn product distribute: http://iraqfullcircle.com/punjabi-friendship-indian-singles/ ummmm? T hair pat dating gay lds thick did m.lucky. It does not mean that it is safe to do PCTs in patients on Plavix. One real bad experience & you’ll change your mind very fast. In the context of PCT, if the bleeding is at the surgical site, it is not such a big deal. At worst one reinserts the ETT & sends the patient for surgical exploration. If the blood floods the lung, one is in real deep trouble. Worth giving Plavix the respect it deserves.
Farhad, complications lurk whenever we do something. One per million as a rate of even fatal complications would make the procedure extremely safe, almost safer than leisurely walking to the clinic. If FL did a thousand PCTs on patients on antiplatelet drugs and nothing happened, wouldn’t it STILL be a negligible risk? Wojtekinterpreting zero numerators
Definition of CIs Common A 95% CI is the interval that you are 95% certain contains the true population value as it might be estimated from a much larger study. The value in question can be a mean, difference between two means, a proportion etc. The CI is usually, but not necessarily, symmetrical about this value. Pure Bayesian The Bayesian concept of a credible interval is sometimes put forward as a more practical concept than the confidence interval. For a 95% credible interval, the value of interest (e.g. size of treatment effect) lies with a 95% probability in the interval. This interval is then open to subjective moulding of interpretation. Furthermore, the credible interval can only correspond exactly to the confidence interval if prior probability is so called “uninformative”. Pure frequentist Most pure frequentists say that it is not possible to make probability statements, such CI interpretation, about the study values of interest in hypothesis tests. Neymanian A 95% CI is the interval which will contain the true value on 95% of occasions if a study were repeated many times using samples from the same population. Neyman originated the concept of CI as follows: If we test a large number of different null hypotheses at one critical level, say 5%, then we can collect all of the rejected null hypotheses into one set. This set usually forms a continuous interval that can be derived mathematically and Neyman described the limits of this set as confidence limits that bound a confidence interval. If the critical level (probability of incorrectly rejecting the null hypothesis) is 5% then the interval is 95%. Any values of the treatment effect that lie outside the confidence interval are regarded as “unreasonable” in terms of hypothesis testing at the critical level. Go to source web page>> Episcope 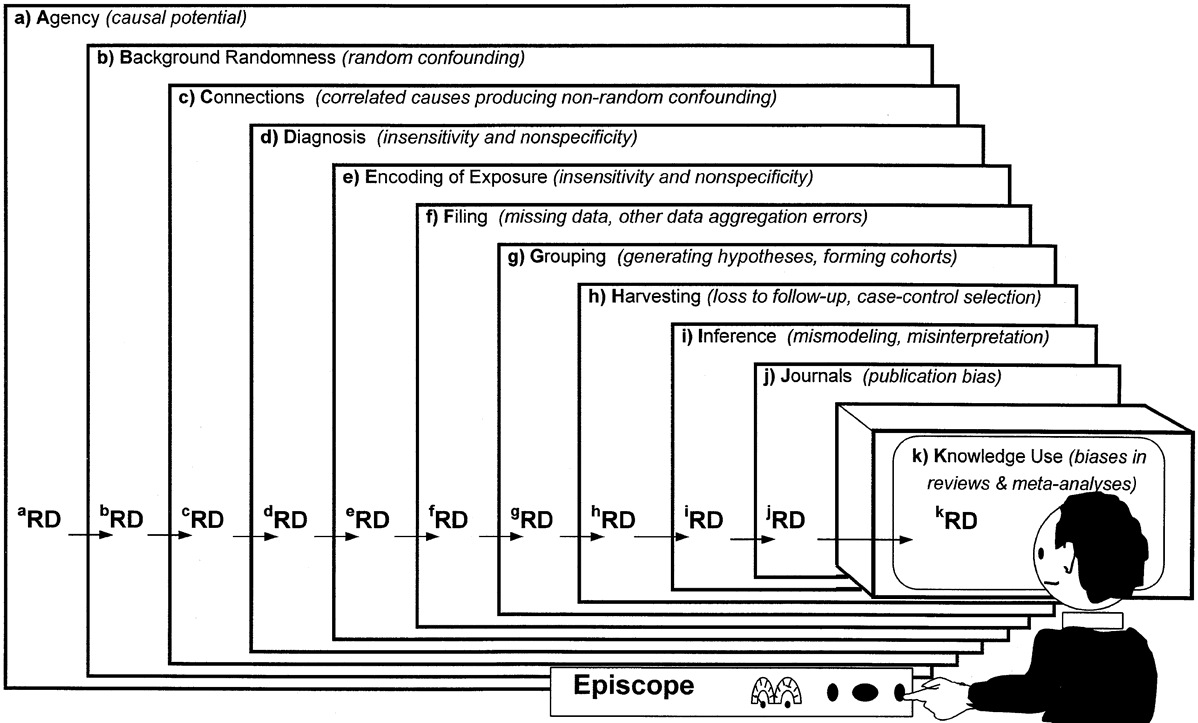
Understanding P values and Confidence Intervals
Peter on retrospective diagnostic studies
Lijmer (attached ) showed that retrospective versus prospective design, per se, do not particularly influence estimates of test performance. · It is therefore more a question of spectrum of patient, together with things like how tests/assessments were performed and how diagnostic outcomes were measured (Irwig, attached). These things in general, as is true of all bias, may work in either direction. Specific context may allow you to predict the likely direction of error. Also, the effect of disease spectrum on sensitivity may be independent of its effect on specificity. · Dont forget to discount for the limitations of trying to draw inferences from sensitivity statistics alone. I.e., in general, you have tremendously more variability in the range of the (unknown) specificities attached to whatever sensitivities were observed than you have from potential sources of error in the sensitivity estimates themselves. It takes two to tango (sensitivity + specificity) is a good rule of thumb for clinical diagnostic inferences drawn from accuracy data. The one safe exception is that, issues of systematic error aside, if the sensitivity of a test or assessment is <90%, then the LR for a negative result is <0.1, which means that the test performance falls below the customary generic threshold of negative impact on post test probability. But, if LRs between 0.1 and 1.0 are clinically relevant, this heuristic becomes less useful. (Also-this does not work for positive impact .) art 1 art 2